

应用层
HTTP
应用层上的协议,都有自己的默认端口。http 默认工作在 80 端口上,http 底层是使用 tcp 进行数据传输的。
那么具体是怎么工作的呢?
- 首先服务器要运转在某个固定 IP 的 80 端口上,等待浏览器的 TCP 连接建立请求。
- 服务器接受浏览器的 TCP 连接
- 浏览器请求建立连接之后,服务器才会同意连接建立请求。之后 web 服务器就有了 socket 指向他们的会话关系。
- 浏览器向服务器发送数据报文,服务器处理完请求,返回响应报文,浏览器解析报文。
- 浏览器主动关闭 TCP 连接(http1.1 不会及时关闭)
响应时间 RTT(round-trip time)
TT 是数据流往返的网络耗时,我们一般的 http 请求与服务端的交互时间
- 一个 RTT 用于建立 tcp 连接
- 一个 RTT 用于发送 http 请求与等待 http 响应
- 传输时间(文件从本地吐出至网络中的时间)
2 个 RTT+传输时间。传输时间其实比较小,如果能共用已经建立的 TCP 连接,那么一般情况下,一次 http 请求只需要一个 RTT 的时间.
持久非持久
我们来看一下非特久和特久。分别对应 HTTP1.0 和 1.1 的两个版本
HTTP 1.0:持久连接。
HTTP 协议的初始版本 1.0 中,每进行一次 HTTP 通信就要断开一次 TCP 连接。也就是说,最多只有一个对象在 TCP 连接上发送,下载多个对象需要多个 TCP 连接。每次 tcp 连接都对应着三次握手和四次挥手,极大的增加了通信开销。
HTTP 1.1:持久连接
多个对象可以在一个客户端和服务器之间的 TCP 连接上传输。只要两端都没有提出断开连接,则持久保持 TCP 连接状态,其他请求可以复用这个连接通道。
而持久又分两种,一种叫流水线 pipeline,另外一种叫 non pipeline 非流水线。
非流水线
多个请求能复用同个连接,但是多个请求得排队,等一个往返后没再发送另一个请求。
流水线
另外一种方式叫流水线方式。一次有十个对象要请求,第一个对象请求发出去,还没回来的时候,我就接着发出第二个、第三个一直到第十个。我们把这种清求的方式,称之为流水方式。
我们当前使用的浏览器默认协议就是 http1.1,也是默认使用流水线模式。每个对象花费有可能只花费一个 RTT。
报文
HTTP 请求报文
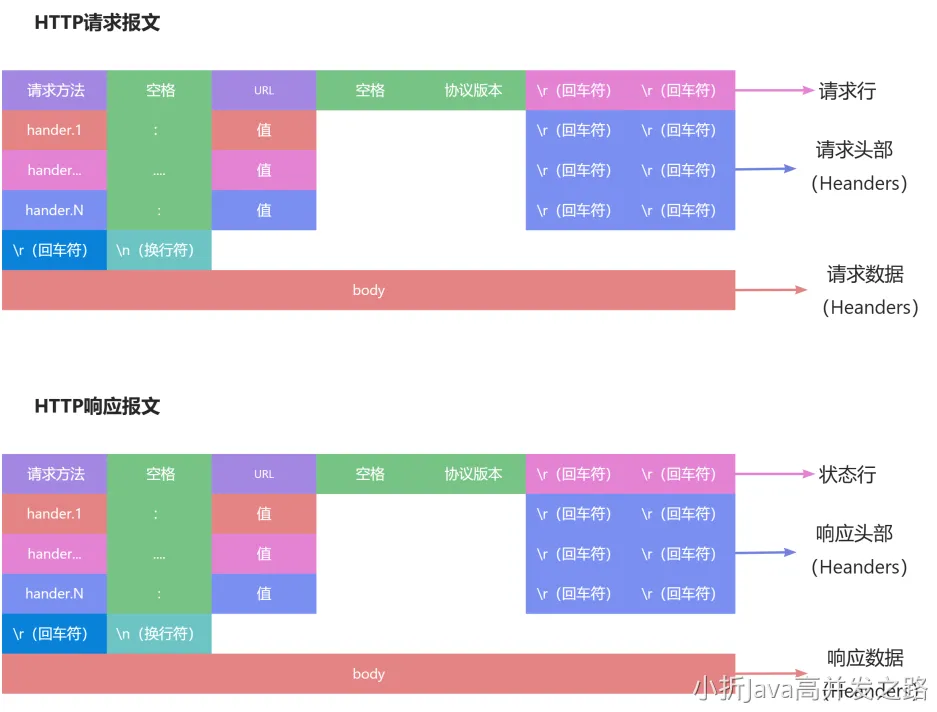
请求报文
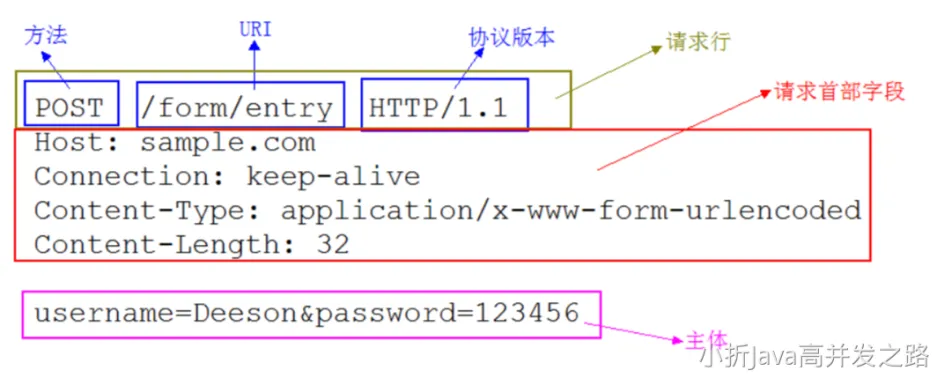
响应报文
请求报文和响应报文的首部内容由以下数据组成。
- 请求行:包含用于请求的方法,请求 URI 和 HTTP 版本
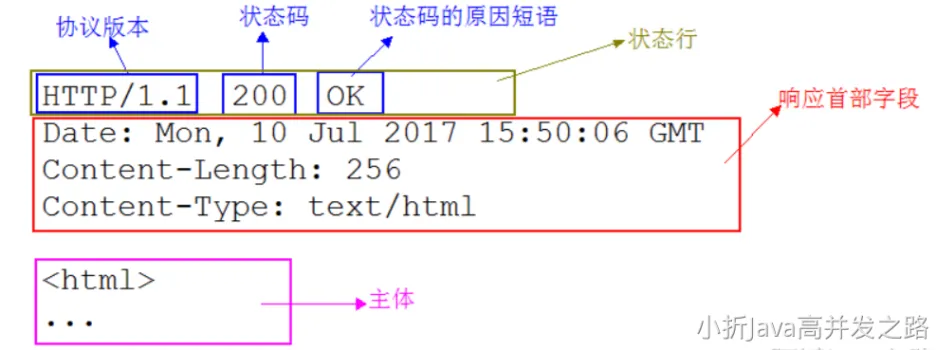
- 状态行:包含表明响应结果的状态码,原因短语和 HTTP 版本
- 首部字段:包含表示请求和响应的各种条件和属性的各类首部
方法类型
HTTP 1.0
- GET:获取资源
- POST:传输实体主体
- HEAD:获取报文首部,不返回报文主体
HTTP1.1 增加
- PUT:传输文件
- DELETE:删除文件
- OPTIONS:用于询问清求 URI 资源支持的方法
状态码
- 1XX
- 2XX
- 3XX
- 4XX
- 5XX
具体可参考 HTTP 状态码
cookie
http 请求是无状态的,所以我需要借助 cookie 标识出与服务器交互过程中的每一个用户。
cookie 技术有 4 个组件:
- 在 HTTP 响应报文中的一个 cookie 首部行。
- 在 HTTP 请求报文中的一个 cookie 首部行。
- 在用户端系统中保留有一个 cookie 文件,并由用户的浏览器进行管理。
- 位于 Web 站点的一个后端数据库。
cookie 交互过程:
- 请求报文到达服务器,Web 站点产生唯一识别码,并以比作为索引在他的后端数据库中产生一个表项。
- 服务器用一个包含 Set-cookie:首部的 HTTP 响应报文对客户的浏览器进行响应。
- 浏览器受到 HTTP 响应报文,会看到 Set-cookie:首部并在它管理的特定 cookie.文件中添加一行,该行包括服务器的主机名和在 Set-cookie:首部中的识别码。
- 之后发往该服务器的每个 HTTP 请求都包括 cookie:首部。
- 服务器可通过 cookie 在数据库中检索信息。
web 缓存
互联网的内容访问遵守二八分布原则,也就是说 80%的人访问 20%的内容。
那么,我们只用安排非常小的缓存,就可以命中很多用户的访问请求,从而减少服务器、网络的负担。
所以说,缓存对客户端来说,它是服务器,而对原始服务器而言,它是客户端。通常缓存是由 ISP 安装的,比如大学、公司、居民区 ISP,然后修改浏览器配置,都指向 web 缓存服务器。
所以,web 缓存也是工作在网络的边缘的一个服务器,事实上,大量工作在应用层的核心支撑应用,都是工作中网络边缘的。
看看浏览器和 web 缓存间初始的交互:
- 浏览器访问 web 缓存服务器。
- web 缓存没有,服务器主动请求目标主机,获取数据。
- web 缓存存下数据,并返回给浏览器。
引入了缓存后,一定会遇到缓存一致性的问题。这时候浏览器客户端可以使用条件 GET,请求报文中包含一个"If-Modified·Since:”首部行。
web 缓存在缓存数据经历了一段时间后,遇到下一次的请求,它主动去找源服务器判断,该数据是否被更新过。
请求只带上头部,开销小。

服务器会返回对应的响应报文 304 代表未修改过

SSL
由于 http 都是明文传输,我们可以采用 ssl 进行加密,ssl 工作在 443 端口上,http+ssl=https。
FTP
ftp 是文件传输协议,客户端向远程主机发送文件或者下载文件。ftp 默认工作在 21 端口。
EMAIL
电子邮件有三个组要组成涪部分
- 客户端代理(阅读器)
- 邮件服务器
- 简单邮件传输协议SMTP
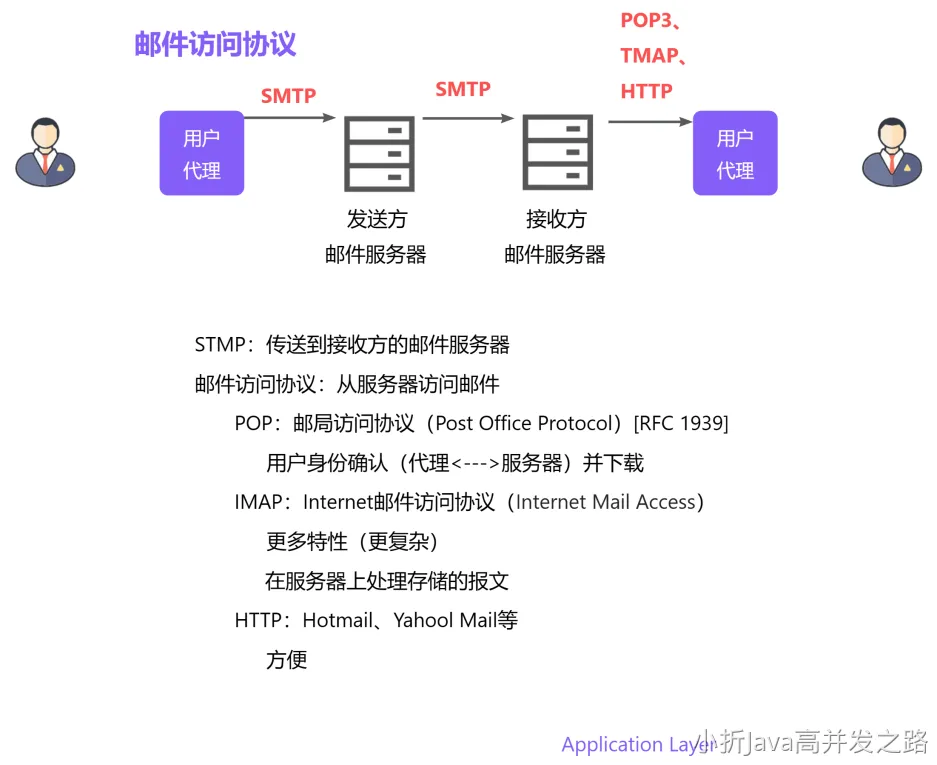
假设用户 A 和用户 B 属于不同的邮件系统 qq 邮箱和火狐邮箱,他们的交互流程是怎样的?
- A 将邮件通过 SMTP 协议传输至 QQ 邮箱服务器。
- QQ 邮箱将邮件通过 SMTP 协议传输至火狐邮箱服务器。
- B 上线后可以通过 http 请求,拉取到最新的未读邮件
DNS
Domain Name System
在 IP 协议中,我们与目标主机交互,需要记住对方的 IP192.168.0.1,这就像我们要记住好多朋友的电话一样。电话也太难记了,所以我们需要有个电话本,记录小明=>183****0606 的对应关系。好比www.baidu.com对应10.0.21.4。
DNS 域名空间结构
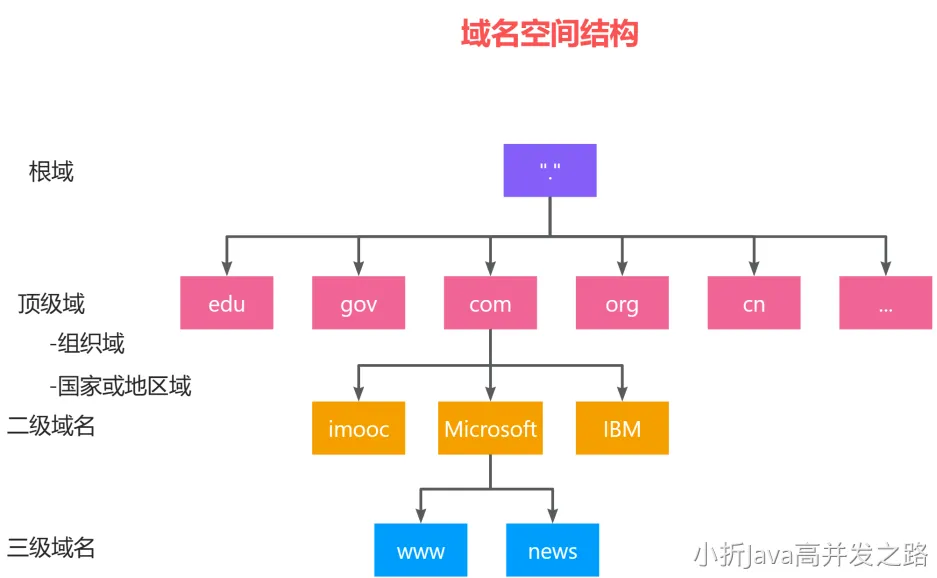
上图展示了 DNS 服务器的部分层次结构,从上到下依次为根域名服务器、顶级域名服务器和权威域名服务器。域名和 IP 地址的映射关系必须保存在域名服务器中,供所有其他应用查询。
DNS 解析流程
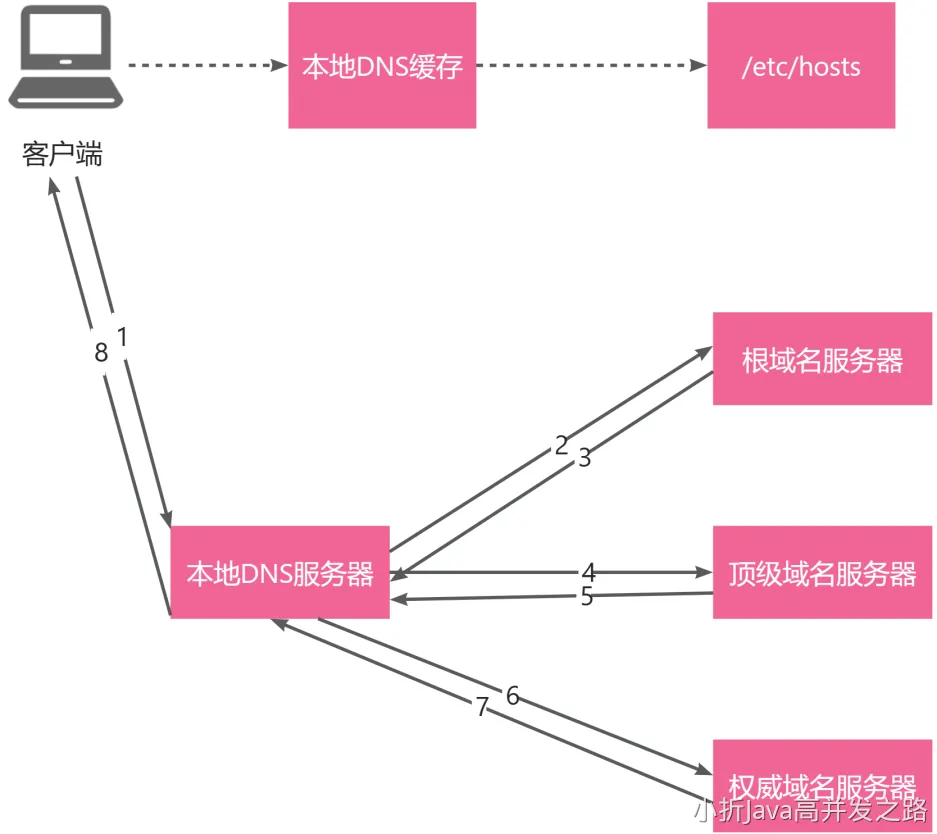
当你输入一个网址的时候:
- 请求本地缓存,查询 host 域名配置。
- 本地缓存没有,查询本地 DNS 服务器。什么是本地 DNS 服务器呢?其实并不是配置在你家里的,而是你的宽带属于哪个服务商,就会使用哪个服务商的 DNS。
- 本地 DNS 服务器没有缓存,查询根域名服务器。
- 根域名服务器会指向顶级域名服务器。
- 顶级域名服务器会指向权威域名服务器。
- 最终拿到权威域名服务器结果,并缓存在本地 DNS 服务器。
域名服务器可以划分为以下四种不同的类型:
- :根域名服务器是最高层次的域名服务器。每个根域名服务器都知道所有的顶级域名服务器的域名及其 IP 地址。因特网上共有 13 个不同 IP 地址的根域名服务器。当本地域名服务器向根域名服务器发出查询请求时,路由器就把查询请求报文转发到离这个 DNS 客户最近的一个根域名服务器。这就加快了 DNS 的查询过程,同时也更合理地利用了因特网的资源。
- :这些域名服务器负责管理在该顶级域名服务器注册的所有二级域名。当收到 DNS 查询请求时就给出相应的回答(可能是最后的结果,也可能是下一级权限域名服务器的 IP 地址)。
- :这些域名服务器负责管理某个区的域名。每一个主机的域名都必须在某个权限域名服务器处注册登记。因此权限域名服务器知道其管辖的域名与 IP 地址的映射关系。另外,权限域名服务器还知道其下级域名服务器的地址。
- :本地域名服务器不属于上述的域名服务器的等级结构。当一个主机发出 DNS 请求报文时,这个报文就首先被送往该主机的本地域名服务器。本地域名服务器起着代理的作用,会将该报文转发到上述的域名服务器的等级结构中。本地域名服务器离用户较近,一般不超过几个路由器的距离,也有可能就在同一个局域网中。本地域名服务器的 P 地址需要直接配置在需要域名解析的主机中。
域名解析分为两种,递归和迭代。我们采用的是迭代的方式,也可以认为是重定向。这样大大节省了根域名服务器的压力。
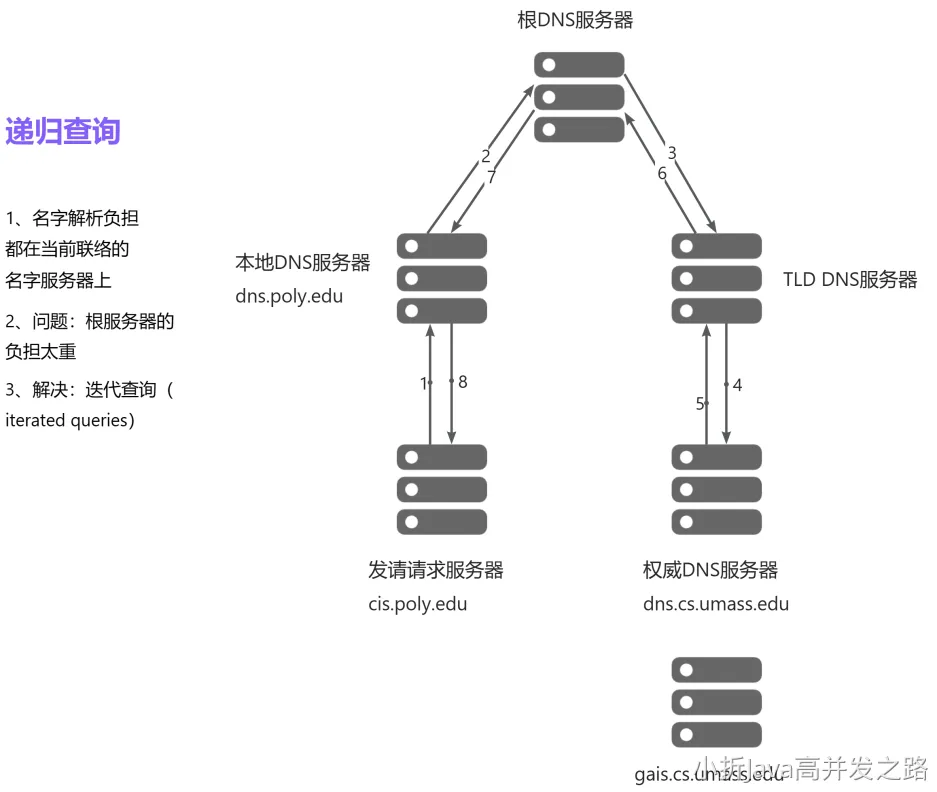
由于域名解析的报文并不长,DNS 域名解析的过程采用的 UDP 的传输协议,大大的增加了传输间的效率。
DNS 解析服务器是分布式的,在主域名解析服务器向其他域名解析服务器直接同步数据时,采用的是 TCP 的传输协议。
P2P 应用
传统的文件分发方式是 C/S 架构,客户端需要下载一个资源,就找服务端下载。如果客户端足够多,服务端响应不了那么多请求,那么服务端只好扩容。哪怕服务端扩容了,有可能接入带宽不够,还得升级带宽。这就导致服务端
需要投入大量的成本。
由此引入了 P2P(Peer To Peer 对等体)的概念。用户和用户之间能够互相传输消息。我们可以设想 P2P 面临的挑战
- 如何定位所需资源的位置
- 如何处理对等体上下线的问题
我们以BitTorrent 协议介绍,BitTorrent 是一种用于文件分发的流行 P2P 协议。
标识文件
每个文件都有唯一的摘要标识我们通过相关的检索服务器,用描述来搜索,就能搜到对应的摘要,也可以称作。
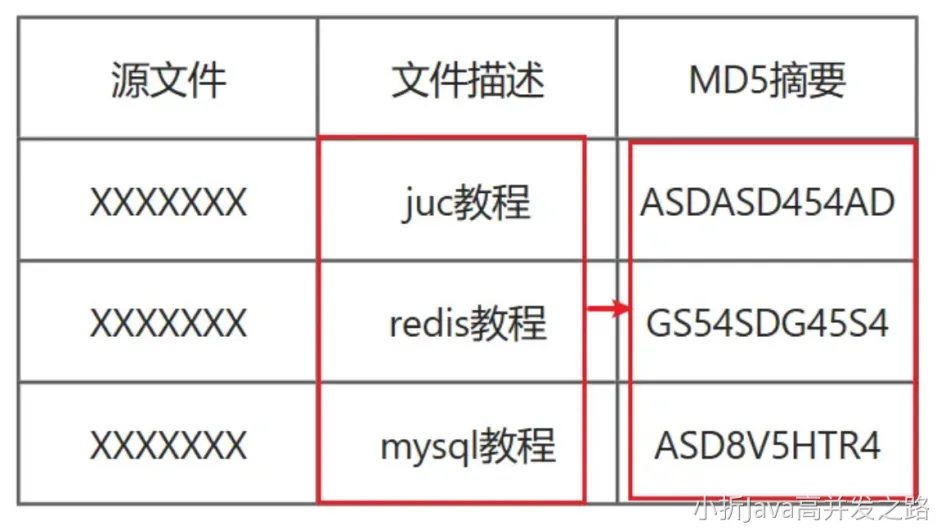
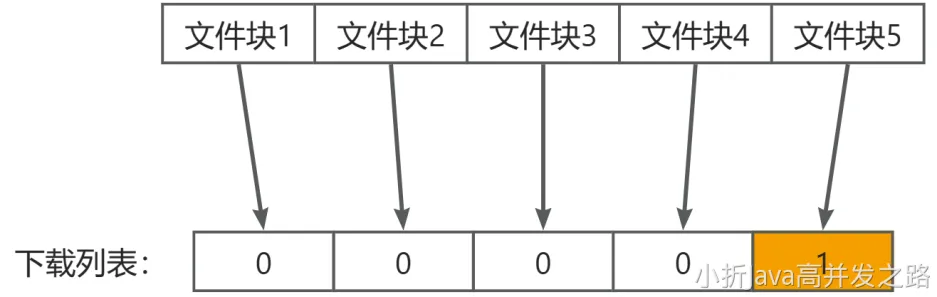
每个文件都被拆分为若干个快,比如 256k 为一块,每块对应着下载列表中的一位。0 代表还没下载,1 代表已经拥有这一块。每个对等体都会维护着自己的一个下载列表。
追踪服务器
所有对等方的上下线,包括下载请求,都会维护在追踪服务器中。
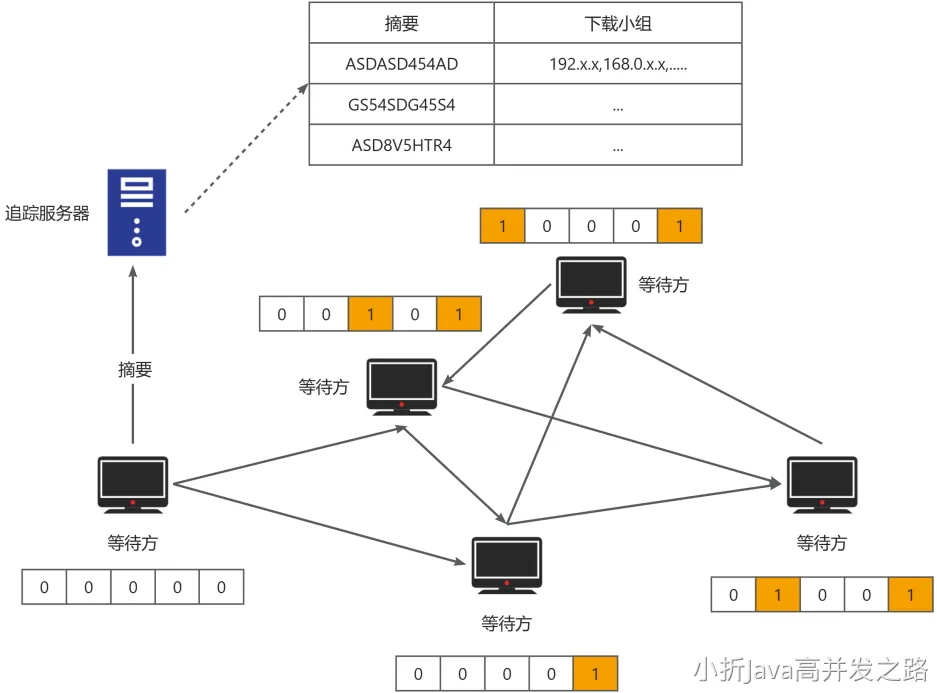
文件下载
新的 peer 加入,将摘要传给追踪服务器,获取到下载小组们的 ip 地址(可能是一次 50 个),然后加入他们,开始下载。
下载遵循几个规侧:
- ,刚加入的对等方,优先去下载小组里最稀缺的文件块,以避免持有稀缺快的服务都下线了。
- ,对等方会对记住给自己提供服务更多的主机,同时也给他更多的上载带宽,这个也被称为一报还一报。
- ,对等方偶尔也会给一些没交互过的主机发送一些文件块,这样期待下一次的请求中,对方能够回报自己。
CDN
Content Delivery Network,即。
构建在现有网络基础之上的智能虚拟网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。
CDN 的关键技术主要有内容存储和分发技术。
简单来讲,CDN 就是根据用户位置分配最近的资源,比如一些视频资源和图片资源。
CDN 一般借助 DNS 来完成请求转发和重定向。
内容请求
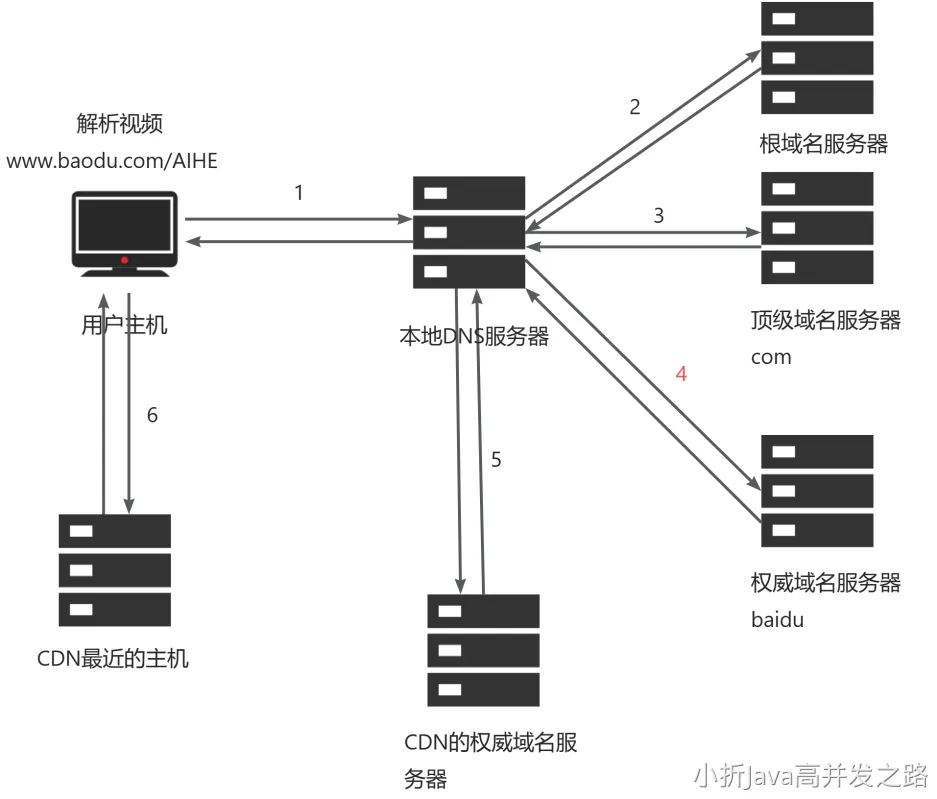
假设用户主机拿到了视频的地址www.baidu.com/AIHD像往常一样解析IP。
本来是在权威域名服务器也就是第四步,需要返回对应的服务器 IP。结果权威域名服务器指向了 CDN 的域名服务器。而 CDN 的域名服务器就会找到最近的 CDN 服务器 IP,返回给用户。用户就拿着 P 从最近的 CDN 服务器中获取资源。
这样接入 CDN 的修改变得特别的小,只需要在自己的权威服务器重定向到 CDN 就行了。
内容修改
同样 cdn 内容加速,也就意味着一致性的问题。服务器内容修改后,需要通知到 CDN 服务商,并且更新其下的 CDN 服务器内容。
Socket 套接字编程
socket 其实就是操作系统提供给程序员操作「网络协议栈】」的接口,说人话就是,你能通过 socket 的接口,来控制协议找工作,从而实现网络通信,达到跨主机通信。
socket 建立之后,我们的消息收发都通过 socket,变得非常方便。Socket 是双方会话关系的本地标识
- 针对 TCP 协议,Socket 是一个四元组(本地 ip,本地 port,对方 ip,对方 port)
- 针对 UDP 协议,Socket 是一个二元组(本地 ip,本地 port)
socket 一般分为和。
TCP 套接字编程
请求流程
服务器端流程:
- 创建服务器套接字(ServerSocket)
- 将套接字绑定到一个本地地址和端口上(bind)
- 将套接字设定为监听模式,准备接受客户瑞请求(listen)
- 阻塞等待客户端请求到来。当请求到来后,接受连接请求,返回一个新的对应于此客户端连接的套接字 socketClient(accept)
- 用返回的套接字 socketClient 和客户端进行通信(IO 流操作)
- 返回,等待另一个客户端请求(accept)
- 关闭套接字(close)
客户端流程:
- 创建客户端套接字(Socket)
- 向服务器发出连接请求(connect)
- 和服务器进行通信(IO 流操作)
- 关闭套接字(close)
Java 代码实现
/**
* 服务器端
*/
public class Server {
public static void main(String[] args) throws IOException {
// 创建一个ServerSocket,用于监听客户端的连接请求
ServerSocket serverSocket = new ServerSocket();
serverSocket.bind(new InetSocketAddress("127.0.0.1", 8000));
// 使用循环不断地接受来自客户端的连接
while (true) {
Socket socket= serverSocket.accept();
// IO流交互通信
PrintStream printStream = new PrintStream(socket.getOutputStream()
, true, "UTF-8");
printStream.println("服务器说:" +
socket.getInetAddress() + ",来了老弟");
BufferedReader in = new BufferedReader(new InputStreamReader(
socket.getInputStream(), "UTF-8"));
System.out.println("来自客户端的信息:" + in.readLine());
// 关闭
printStream.close();
in.close();
socket.close();
}
}
}
/**
* 客户端的代码
*/
public class Client {
public static void main(String[] args) throws IOException {
// 创建一个Socket,向服务器发出连接请求
Socket socket = new Socket();
socket.connect(new InetSocketAddress("127.0.0.1", 8000));
// IO流交互通信
BufferedReader reader = new BufferedReader(new InputStreamReader(
socket.getInputStream(), "UTF-8"));
System.out.println("来自服务器的信息:" + reader.readLine());
PrintStream ps = new PrintStream(socket.getOutputStream(), true, "UTF-8");
ps.println("客户端向你问好");
// 关闭
reader.close();
socket.close();
}
}UDP 套接字编程
请求流程
服务器端流程:
- 创建套接字(DatagramSocket)
- 将套接字绑定到一个本地地址和端口上(bind)
- 阻塞等待接收消息(receive)
- 收到的消息被封装在 DatagramPacket 里,里面有对方的 ip 和端口
- 可以根据对方的 DatagramPacket 再像对方发送消息
- 关闭套接字(close)
客户端流程:
- 创建客户端套接字(Socket)
- 创建交互数据报(DatagramPacket),并指定对方 ip 和端口
- 发送消息(send)
- 关闭套接字(close)
Java 代码实现
public class UdpServer {
public static void main(String[] args) throws Exception {
System.out.println("----接收方启动中-----");
//1.使用DatagramSocket 指定端口 创建接收端
DatagramSocket server=new DatagramSocket(8000);
//2.准备容器 封装成DatagramPacket包裹
byte[] container=new byte[1024*60];
DatagramPacket packet=new DatagramPacket(container,0,container.length);
//3.阻塞式接收包裹receive(DatagramPacket p)
server.receive(packet);
//4.分析数据 byte[] getData() getLength()
byte[] datas=packet.getData();//获取数据
int len=packet.getLength();//获取数据长度
//操作获取到的数据
System.out.println(new String(datas,0,len));
//返回给客户端消息
packet.setData("服务器收到了".getBytes());
server.send(packet);
//5.释放资源
server.close();
}
}
public class UdpClient {
public static void main(String[] args) throws Exception {
System.out.println("----发送方启动中-----");
//1.使用DatagramSocket 指定端口 创建发送端
DatagramSocket client=new DatagramSocket(8888);
// 2.准备数据一定转成字节数组
String data="客户端发送请求";
byte[] datas=data.getBytes();
// 3.封装成DatagramPacket包裹,需要指定目的地
//传入参数为 (数据集,数据初始位置即0,数据长度,
//接收端对象(接收端地址,接收端端口))
DatagramPacket packet=new DatagramPacket(datas,0,datas.length,
new InetSocketAddress("localhost",8000));
// 4.发送包裹send(DatagramPacket p)
client.send(packet);
//接受服务器返回的消息
client.receive(packet);
//操作获取到的数据
System.out.println(new String(packet.getData(),0,packet.getLength()));
// 5.释放资源
client.close();
}
}我们可以发现,tcp 和 udp 各自用一套端口,哪怕都是 8000,但是互不冲突
查缺补漏
应用层是协议和支撑应用最多的一层,学完后,我们可以看几个八股文,看看自己是不是都掌握了(答案在最后的八股文章节)。